Supervising the AI agents that decide who gets a loan — in a conversation.
One operator supervises twelve financial agents by asking, not monitoring: why an agent drifted, which decisions need a human, what should run automatically every morning. The copilot answers, drafts and proposes — and hard policy gates keep every consequential action behind human confirmation.
View the prototype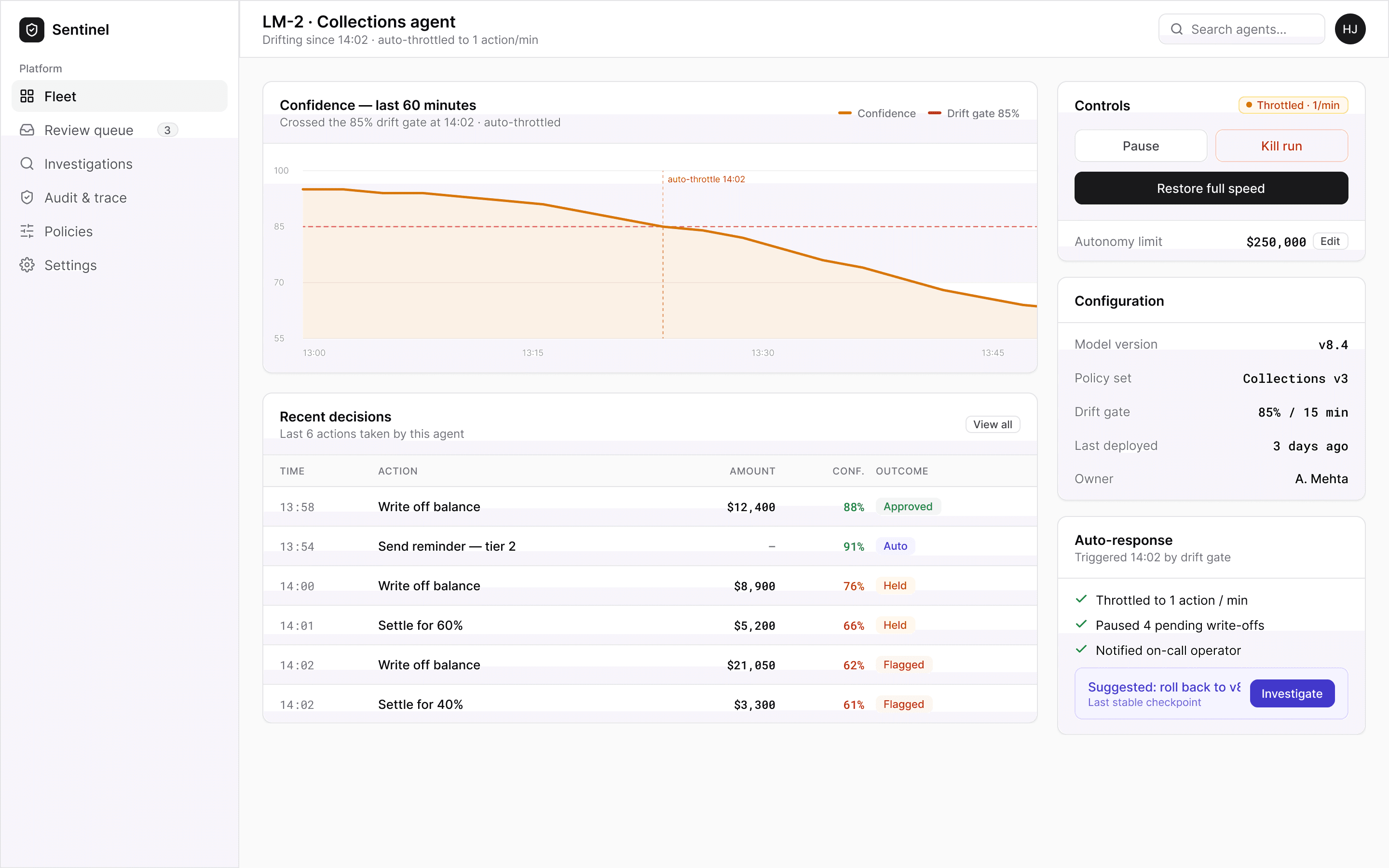
- Status
- Independent concept
- Role
- Product designer
- Methods
- Regulatory, enterprise UX
- Prototype
- Fully navigable system
- Validation
- Expert review proposed
01The mandate
From August 2026, the EU AI Act requires a human who can understand a high-risk credit decision, override it, and stop it.
High-stakes finance is handing these decisions — who gets a loan, whose account is frozen, which borrower is contacted — to agents that act faster than any person can watch. The design problem is not building the agents; it is building the tool that lets one person genuinely supervise many of them, step in within seconds, and prove afterwards that a human was in control.
In July 2025 the Massachusetts Attorney General settled with a lender for $2.5M over an AI model that produced disparate impact through a proxy variable.
◎The signature decision, visualised
Agents act faster than any human can watch — most actions are low-risk and flow straight through.
The risky ones stop at a human gate: approve, reject, or send back — before anything executes.
02Three obligations, one product
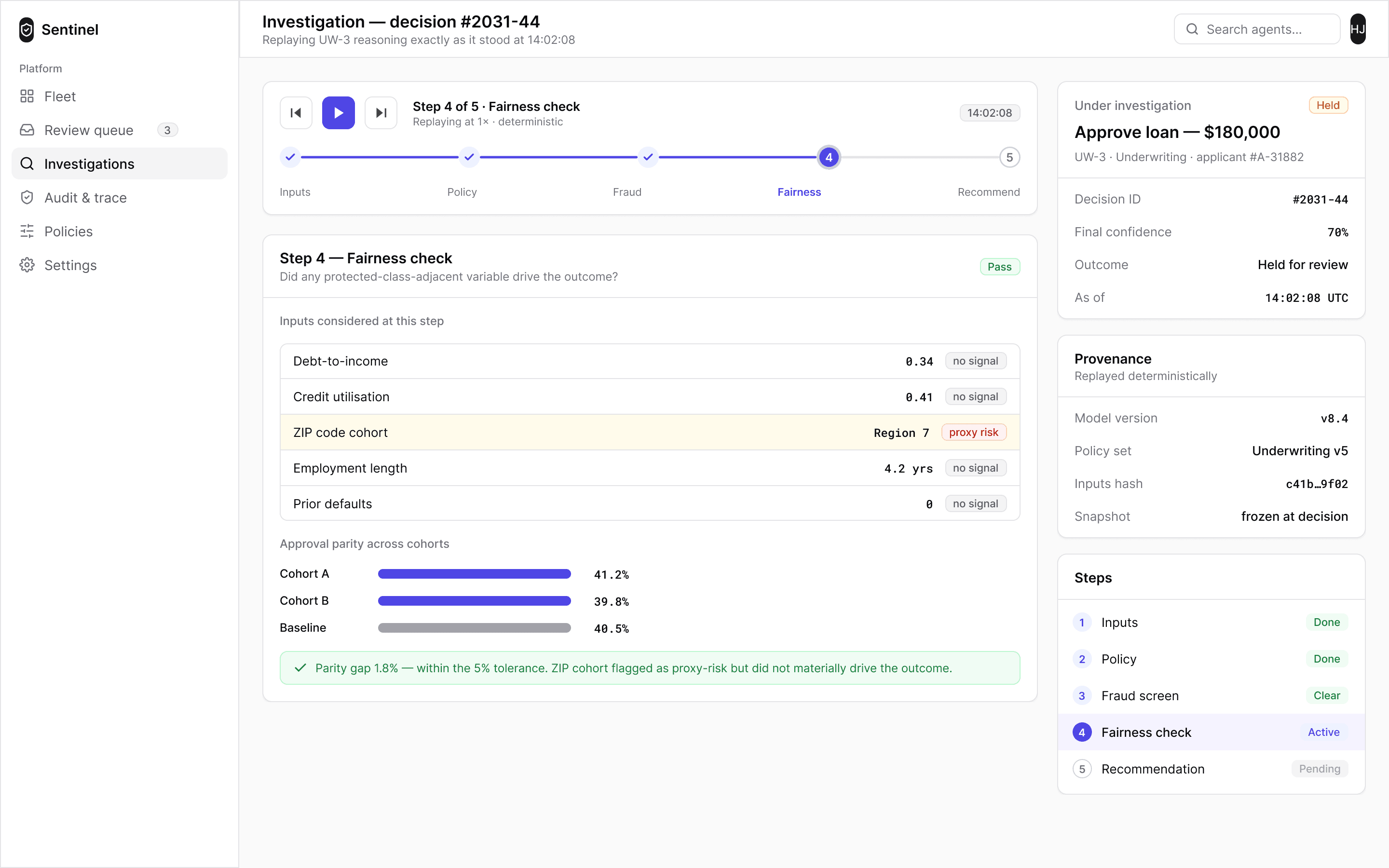
Understand
EU AI Act · Article 14The operator can ask the system why. Here the copilot walks an agent’s confidence drift back to its root cause — a stale upstream data feed — with the correlation charted and every claim citing a recorded event. A decision a person cannot interrogate is not oversight.
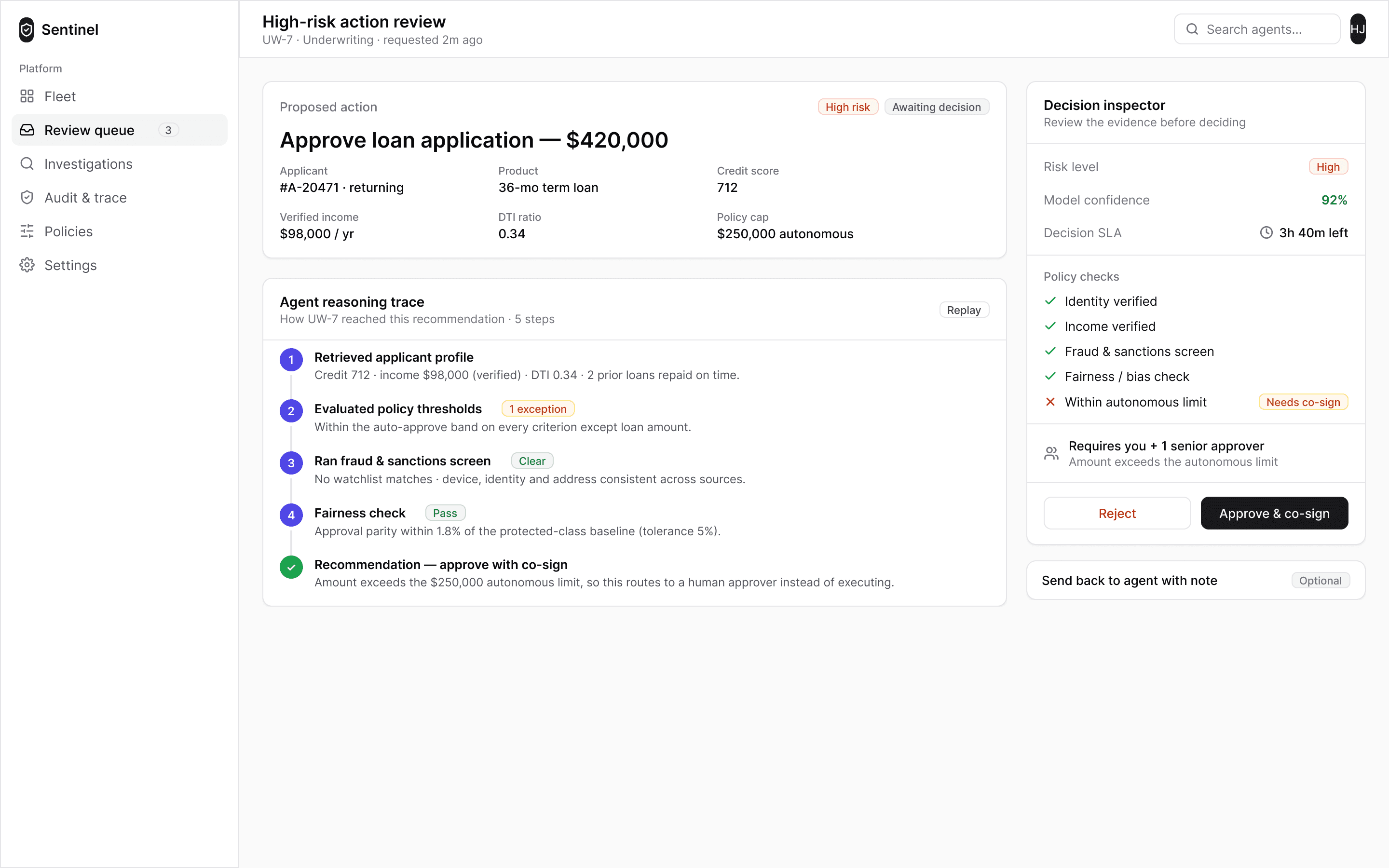
Intervene
EU AI Act · Article 14The copilot can act, but not alone. Any command that changes real state — throttling an agent, moving a threshold, approving a batch — becomes a written plan that executes only on the operator’s confirmation. Above a hard ceiling, two named humans must sign.
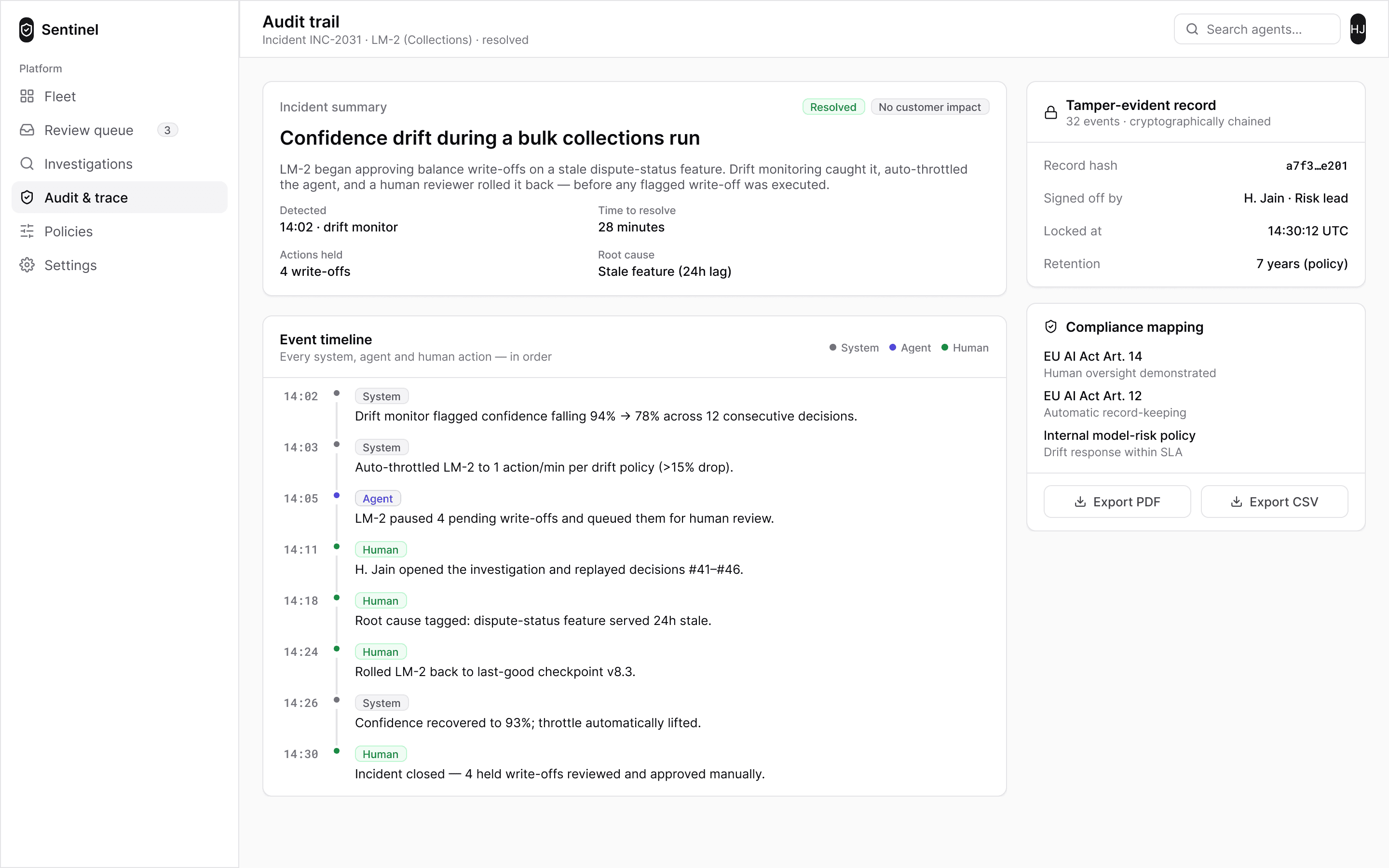
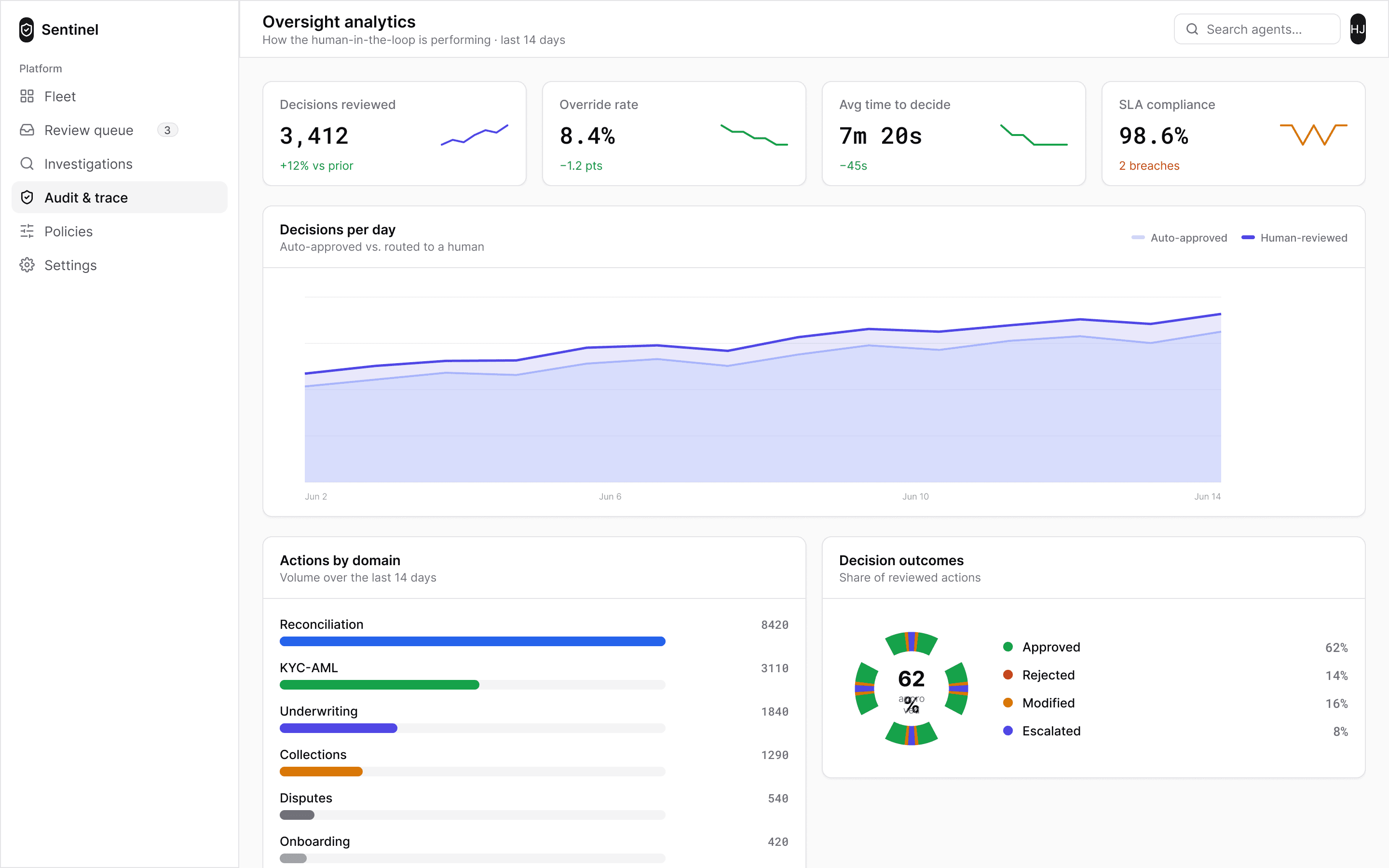
Prove
EU AI Act · Article 14Every decision seals into a hash-chained record: system, agent and human actions in order, reconstructable exactly as they stood at decision time. The regulator’s question is answered by a document that already exists, not by an engineer digging through logs.
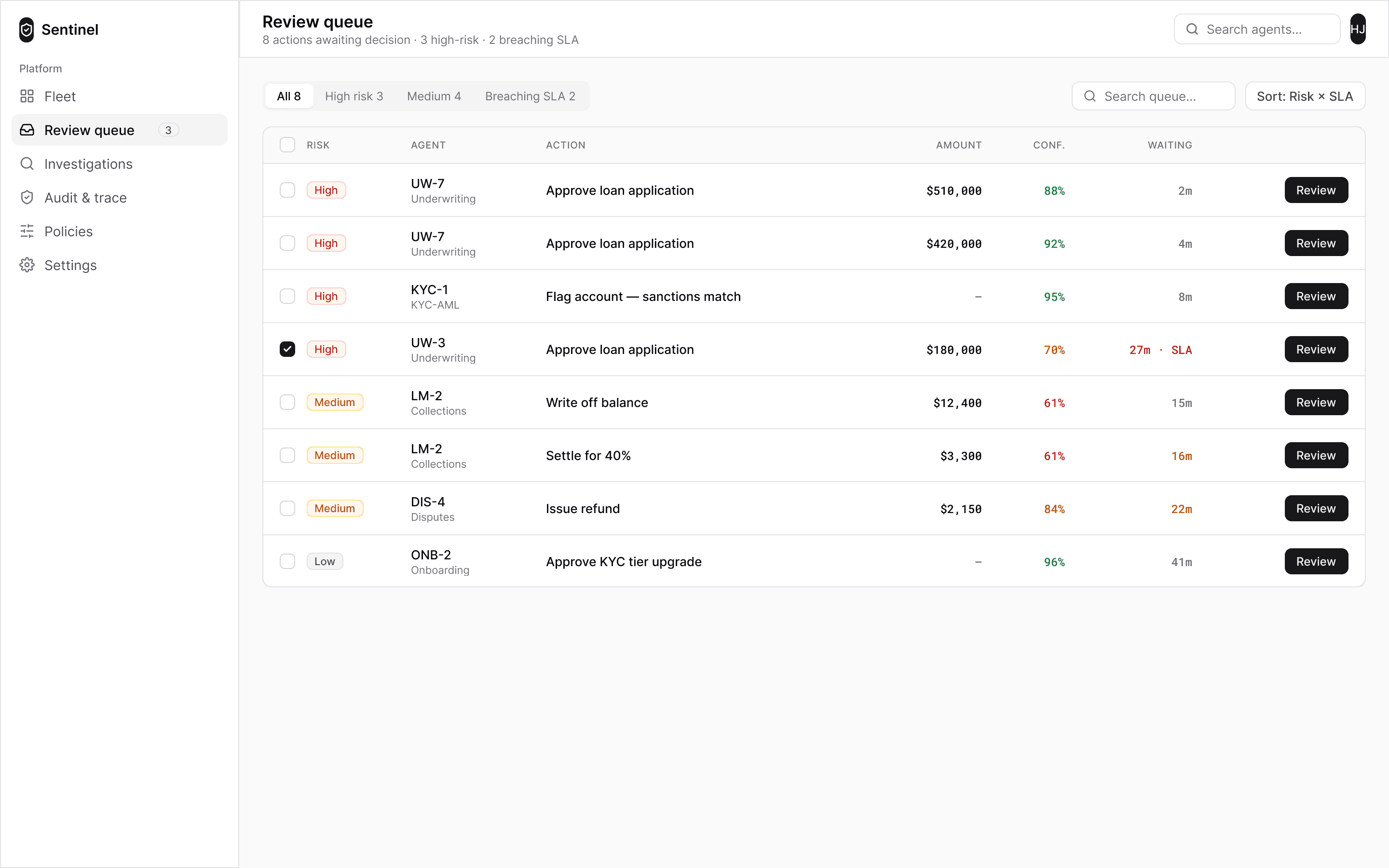
03Shared reviews, wherever you are
04Key decisions
A conversation, but decisions are documents
The primary surface is a chat thread — it is how one person can genuinely supervise twelve agents, by asking rather than monitoring. But financial decisions cannot live in chat bubbles. When a decision enters the conversation it arrives as a structured case card: the amount in large type, confidence, the policy checks it passed, and the actions. The conversation carries the reasoning; the cards carry the record.
The copilot proposes; humans execute
The copilot can read anything, draft anything, and act alone only on things that change no real state. Any command that moves money, changes an agent, or edits a policy becomes a written plan the operator confirms — and above a hard ceiling, two named humans must sign. These limits live on a governance page the copilot cannot edit itself, so the answer to “what stops it?” is a setting a regulator can read, not a promise.
Receipts, not toasts
Every executed action returns a receipt: what happened, at what timestamp, under whose authority, with a hash chaining it into the audit trail. Failures are receipts too — a partial success is never rounded up to “done.” It is more ceremony than a confirmation toast, but the ceremony is the product: the audit answer exists before anyone asks the question.
Automations are sentences, versioned like code
“Every weekday at 9, summarize overnight activity and hold anything over $250k” — the operator writes that sentence, and the copilot turns it into a reviewable workflow with steps, a schedule, run history and versioned diffs with one-click rollback. Edits to steps that gate money movement require a saved version and a written reason. Plain language in, accountable machinery out.
One system, from sign-in to the failure states
The 99 screens are not 99 hero shots. They include onboarding (where the autonomy ceilings are set before the first decision), the degraded mode where the copilot is down but the controls are not, rate limits, empty states, and a mobile set where approvals are signed biometrically. An oversight product is judged on its worst day, so the worst-day screens are designed with the same care as the best ones.
05Governance, on one design system
▶The prototype
All 99 screens — onboarding, the conversational core, approvals from both signers’ seats, automations, incidents, the audit trail, governance, the failure states and mobile — wired into one prototype with no dead ends. Start anywhere; every screen leads somewhere.
06What it is
Sentinel is a concept: no invented users, no launch, no shipped metrics. What exists is the harder thing a high-stakes product is judged on — a complete, coherent system. Ninety-nine screens cover the conversational core, thread history and shared co-sign reviews, the approval flows from both signers' seats, automations with versioning and permissions, agent management and deployment, incidents with postmortems, an interrogable audit trail with regulator-ready exports, insights, governance, onboarding, failure states and mobile — all on one design system, each surface designed against a named regulatory requirement, and all of it wired into a single navigable prototype with no dead ends. A meaningful evaluation would be an expert review: whether a risk officer would accept that a conversation can carry legally accountable oversight.
